Testing robotics systems in fast-paced startups

Testing robotics systems is hard. Based on my experience working at startups with fewer than 200 employees and fewer than 100 robots providing RaaS using fleets of indoor mobile robots or lines of robot manipulators, the main reasons for the difficulty were as follows:
- Edge cases and corner cases in production environments.
- The difficulty of using simulation.
- Challenges with adopting automation.
Why is Testing Robotics Systems Hard?
In production, I’ve encountered various edge cases and corner cases:
- Edge cases for robotics algorithms. Input spaces for robotics algorithms, such as perception, control, and motion planning, are vast and challenging to effectively cover for edge cases; there is always a specific layout that causes navigation failures or a particular scene with specific objects that leads to grasping failures. Characterizing such instances is difficult and algorithm-dependent, which complicates the testing setup.
- Rare hardware issues. Rare hardware issues that are not (directly) detectable are the worst, such as a small damage in the robot cell structure that requires adjusting the collision map. Anticipating such issues requires input from domain experts (e.g., mechanical or firmware engineers), who may not be easily accessible and speak different jargons and reproducing them often requires changing interfaces, which can be expensive (e.g., it becomes yet another layer to maintain).
- Subtle regression. The complexity of robotics systems makes it challenging to establish a robust regression testing pipeline. For example, handling low-frequency flaky tests, implementing robust test selection and prioritization[^2] is difficult and hence elusive bugs slip back into the production code. Performance regressions are particularly challenging–especially ones caused by low-level concurrency issues[^3], as they are subtle and require expensive measures such as repeated end-to-end tests and delicate statistical methods to detect.
- Unexpected peak load condition/usage pattern. It is common for multiple (custom) software, such as core robotics, monitoring, and infra-related software, to run in parallel. Unexpected high demands can adversarially impact your program, e.g., by consuming all of the available resources. Anticipating and recreating such situations is challenging, especially when dealing with (custom) software at all levels, including firmware and system software.
Using simulation for testing robotics systems effectively is not as easy as it seems.
- Inadequate usage. I find that simulation testing is most useful for end-to-end testing of robot applications. However, I often encounter test cases that would benefit from using other tools and techniques (e.g., for efficiency). All too frequently, I come across test cases for robot behaviors (e.g., implemented in finite state machine or behavior tree) that use simulation, making the test cases much more expensive than they need to be. In such cases, using alternatives like fake or model-based testing[^4] would be much more efficient, as they can be used to only “simulate” the directly relevant modules[^5]. This often stems from organizational issues, such as unclear boundaries between teams that result in poorly defined interfaces and testing strategies[^6] or more typical insufficient allocation of time for testing/addressing technical debts (e.g., in favor of prioritizing other deliverables).
- Generating test cases. Even with simulation libraries that provide high-level interfaces for building scenarios, creating effective test scenarios is challenging. Creating a single simulated environment for end-to-end testing alone is laborious enough, so diversifying the test scenarios (e.g., to cover extreme cases) becomes a nice-to-have[^7]. There are commercial products that address this issue (e.g., AWS RoboMaker WorldForge), but they are not easy for smaller organizations (i.e., startups) to integrate due to reasons such as integration cost, vendor lock-in, etc.
- Expressing specifications. Specifications for many robotics programs, e.g., those involving perception, motion planning, and behaviors, are difficult to express due to their spatiotemporal nature. This leads to verbose and unorganized (e.g., containing duplicates) test code, which makes it difficult to maintain and scale.
- Managing infrastructure. I haven’t met a single person who loves managing simulation testing infrastructure, e.g., for continuous integration. Simulation test code is expensive to run, requires special hardware such as GPUs, and is difficult to optimize and move around (e.g., in cloud environments). This leads to a poor developer experience and can even result in the disabling of simulation testing.
Automating robotics software testing is still hard.
- Challenges with automating build and deployment.
Here are tech talks and a blog post that shed light on this topic:
- Packaging ROS with GitHub Actions from PICKNIK Blog, 2023.
- Building Self Driving Cars with Bazel from Cruise, BazelCon 2019 - shares Cruise’s experiences with building and testing robotics software at scale
- The landscape of software deployment in robotics from Airbotics - summarizes the typical challenges with deploying robotics software
- Physical continuous integration on real robots from Fetch, ROSCon 2016 - shares Fetch’s experience with setting up and using a physical continuous integration pipeline
- No standard. Automating the testing of software requires agreements among engineering teams on build, deployment, and test models. Given how robotics brings multiple communities together, such as research (e.g., computer vision, robotics), web development (e.g., frontend, backend), DevOps, embedded, etc., reaching such an agreement, or even discussing ideas (e.g., due to different backgrounds), is difficult. While the Robot-Operating System (ROS) and the communities around it have made significant progress in this regard, the lack of standards still seems to be a significant problem in organizations.
Where to Start with Testing: General Techniques
To figure out where to start with testing a robotics system, I use the followings:
- Prioritization framework for creating tests.
- Systematic procedure for identifying what to test.
The techniques discussed in this section are general/not-so-technical and are mostly aimed at addressing the abovementioned challenges regarding “edge and corner cases in production environments”.
Eisenhower Matrix for Test Prioritization
In robotics startups that build complex systems, creating comprehensive test suites is impossible. To produce high-impact tests within the time budget, I use my adapted Eisenhower Matrix to prioritize a list of failure scenarios by first categorizing (potential) failure scenarios according to their (expected) frequency and risk.
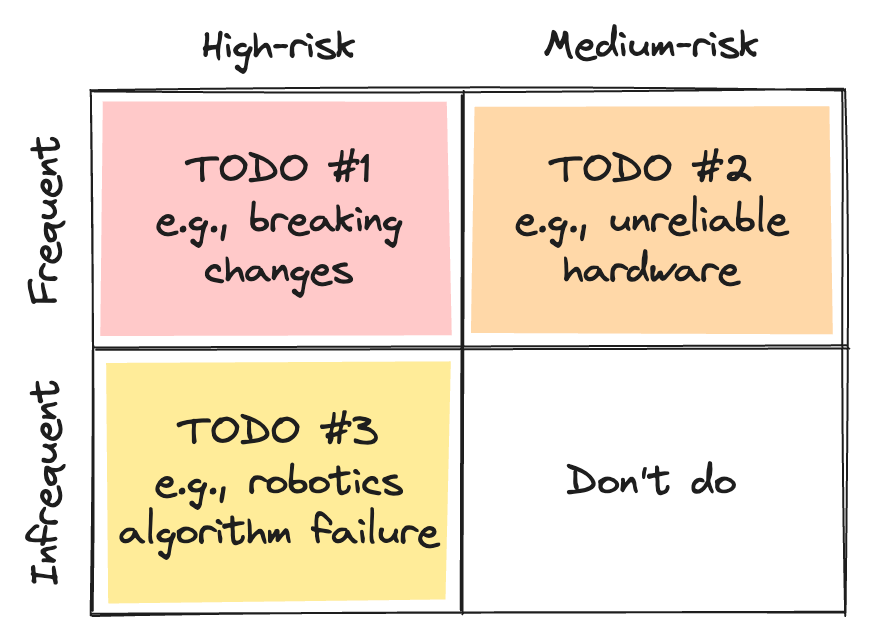
- First Quadrant (upper left): frequent and high-risk. In Quadrant 1 (Q1), I place failure scenarios that need to be covered immediately, e.g., that I hear all the time from internal communication channels, such as introducing breaking changes to APIs and dependencies.
- Second Quadrant (upper right): frequent and medium-risk. In Quadrant 2 (Q2), I place failure scenarios that occur frequently but allow continued operations with short downtime like unreliable hardware or unresponsive user interface issues with well-established alerts and recovery procedures.
- Third Quadrant (lower left): infrequent and high-risk. In Quadrant 3 (Q3), I place failure scenarios that occur rarely but causes significant disruption in operations such as core robotics component failure scenario or unexpected peak usage pattern.
- Fourth Quadrant (lower right): infrequent and medium-risk. In Quadrant 4 (Q4), I place failure scenarios that occur relatively infrequently and allow continued operations.
The placement of example failure scenarios in quadrants will differ across companies. For instance, depending on the maturity of the robot product/prototype or the amount of time invested by the engineering team in designing the system, an unreliable hardware failure scenario may belong in Q1 (e.g., if it is causing multiple issues) or a robotics algorithms failure scenario may belong in Q2 (e.g., if the failure is not catastrophic or easily recoverable). In general, I create or improve tests for one quadrant at a time, in increasing order. After working on tests for Q1, I move on to tests for Q2 before addressing those for Q3. This is because creating tests for Q3 requires a significant time investment, for example, to ensure the reproducibility of the failure. Usually, there is no time available to work on tests for Q4. But adjustments should be made to meet organization-specific requirements and constraints.
Test Scenario Identification Procedure
So far, I have assumed that the failure scenarios to test are known; however, this is usually not the case. To determine what to test, I follow these steps:
- Gain access to internal alerts, dashboards, and logs. Investigating recently reported problems or analyzing the latest trends using monitoring tools[^8] is the easiest way to identify high-risk failure scenarios. If monitoring tools are not set up (e.g., in smaller companies), I get involved in operations work, which is another way to uncover potential high-value tests to create.
- Identify interface and service boundaries. Understanding how software components interact with each other provides insights into potential integration failures and their impact. I start by looking for internal documentation with system diagrams (or examining the codebase and creating them if such diagrams don’t exist) and ask questions such as: which interactions must not fail? which interactions are changing frequently? Such exercises reveal missing must-have contract tests or high-impact opportunities to improve integration tests.
- Identify implicit dependencies. I consider edge cases such as low resources, unexpected hardware states, or unseen inputs to robotics algorithms (e.g., those that crash applications) as unmet runtime dependencies. Taking this view nudges me to specify these not-well-understood requirements for keeping the system (or “implicit dependencies”) well-behaving as explicitly and clearly as possible. Once defined, such requirements can be used to create extreme failure scenarios to test.
Ensuring Testability as a Startup Grows
Below, I share my insights on key practices to employ at each growth stage/funding round of robotics startups. The real motivation behind testing is the reliability (e.g., of the provided service), and so the shared key practices below cover related areas such as debugging and observability[^9].
If you have experience with SaaS/web service startups, you might notice that the RaaS/robotics company size (i.e., the number of employees) at each growth stage is larger, and some key practices occur later in robotics startups. This is because RaaS/robotics products not only consist of a more diverse set of software components but also require additional teams like electrical/firmware engineering, mechanical engineering, and manufacturing operations.
5-20 Employees
At this stage, startups are likely to have fewer than 5 customers/design partners and a handful of developers who are relentlessly building (and fixing) major components of the company’s first product. The goal of the startups is to prove the value of their product to their (rather forgiving) customers by succeeding in basic tasks performed by robots as much as possible. For example, a delivery robot should navigate without colliding with obstacles, and a robot manipulator should pick and place objects without dropping them in customers’ (production) environments.
Key Practices:
- Setting up continuous integration or nightly tests (e.g., using Jenkins, GitLab CI/CD, GitHub Actions, or Debian build farm) with end-to-end tests involving a high-fidelity simulator (e.g., Gazebo) to quickly smoke test rapidly changing codebases.
- Collaborating on internal communication channels (e.g., Slack) and utilizing a (custom) teleop solution (e.g., built on MQTT, WebRTC) to quickly respond to critical incidents.
- Creating metrics and dashboards to track business-critical measures (e.g., using Grafana/Prometheus) such as the number of deliveries/distance traveled, throughput/object knitted to guide all developers/employees at a high level.
21-200 Employees
Startups at this stage start expanding their customer base and aim to scale their operations to deploy and handle, for example, more than 100 robots. The companies now have (small) teams of developers working on enhancing the robustness of core robotics software components to handle diverse environments of new (and unforgiving) customers, providing a non-beta-user-acceptable user experience (e.g., by building proper onboard and/or desktop UIs), and/or infrastructure to scale operations. The robotics system powering the product becomes much more complex, and to manage such complexity, its architecture becomes more modular, composable, and distributed, and boundaries/ownerships occur.
Key Practices:
- Employing narrow integration tests and contract tests using test doubles like fakes and spies—sometimes going as far as implementing low-fidelity simulators with them (e.g., using pytest, GoogleTest) to test each team’s evolving software component in isolation and complex interactions between such components, efficiently.
- Establishing a deployment strategy with rollback support (e.g., using tools that enable infrastructure-as-code/gitops like Ansible, Terraform and support over-the-air updates, etc.) to avoid manually applying untrackable hotfixes in fear of losing customers.
By the way, this practice is nontrivial to achieve for technical and cultural reasons; for more information, see “The landscape of software deployment in robotics” from Airbotics. Typically, adopting a deployment tooling sparks discussions like adopting cloud-native tooling or not, which then sparks discussions on system launching mechanisms, and so on. - Implementing nightly tests on real robots in a mirror warehouse or manufacturing line or physical continuous integration in a production-like environment to prevent edge and corner cases and performance regressions in production environments as much as possible.
- Structuring and centralizing logs (e.g., structlog, spdlog, and Loki, ELK, Splunk) to track performance across growing fleets and enable dynamically querying information for fast debugging or monitoring, e.g., with robotics-specific metrics. In addition, centralizing data would be ideal; however, given the large size of robotics data, doing so requires more care and resources—which usually becomes possible to afford in the next stage.
- Implementing a data record and replayer and visualizer (e.g., rosbag and RVIZ, Foxglove Studio, or custom-built ones) to enable debugging or optimizing robotics algorithms running in distributed systems. By the way, building a performant data record and replayer, e.g., that works well with both real robots and simulators, is no joke; there are issues like not being able to record or replay data fast enough, doesn’t work well with simulators that run slower or faster than real-time, etc.
- Utilizing (custom) fleet operation solution to scale teleop-based incidence recovery (e.g., more robots to monitor/rescue per person), open up such operations to non-developers, etc.
201-2000 Employees
I have not been employed by a robotics company that had more than 200 employees. The insights in this subsection are derived from (1) my experience at a company was actively preparing for the expansion beyond 200 employees and (2) indirect experiences shared by my colleagues in the robotics field. In other words, please take the suggested key practices with a grain of salt.
Robotics companies at this stage have experienced significant growth and have a large customer base. Their goal is to further scale their operations and efficiently handle a substantial number of robots, potentially exceeding 1000 units, without compromising performance. The company now consists of multiple teams working on various aspects of the robotics system, including core software development, fleet management and user experience enhancement, custom hardware integration and test, infrastructure scalability, and customer support. Additionally, the focus expands beyond purely technical challenges to encompass broader organizational considerations, such as team structure, talent management, strategic partnerships, and market expansion.
Key Practices:
- Implementing an advanced test automation framework that encompasses a wide range of tests, including unit, integration, performance regression (e.g., via hardware-in-the-loop), and security tests. To improve testing efficiency, the company utilizes techniques such as test impact analysis and test selection and prioritization, which identify the most critical tests and prioritize their execution. Furthermore, they leverage cloud resources to run a large number of simulation-based end-to-end tests in parallel, accelerating the testing process.
- Enhancing developer productivity through faster iteration, improved debugging and testing tooling, and ultimately aiming to enhance system reliability. At this stage, companies have the resources to invest in infrastructure and pipeline improvements. This includes setting up cloud development environments utilizing platforms like GitPod, Coder, and DevZero. Additionally, efforts are made to speed up build times through techniques such as remote caching. Streamlining code review and merge progress is achieved using tools like Merge Queue. Furthermore, specialized tooling is developed to cater to the specific needs of the company. For instance, enhancing the data record and replayer to support streaming robotics data enables faster debugging by bypassing the need to download large datasets onto local development machines. The data record and replayer are also optimized to handle high throughput and enable navigation between critical timestamps. Another example of specialized tooling is the creation of a test scenario generator, which automates the generation of realistic test scenarios, enhancing test coverage and enabling the identification of edge cases and potential failure scenarios.
- Establishing a formalized release management process that includes thorough testing, staging environments, and controlled deployments across all teams involved in building a product. This involves standarizing continuous integration and continuous deployment (CI/CD) practices across teams, maintaining release documentation, and employing release dashboards. The company also invests in advanced deployment and orchestration tools such as Terraform, Docker, and Kubernetes to facilitate large-scale, cross-team deployment and operation of a diverse fleet, encompassing robots, peripheral devices (e.g., elevator controller, manufacturing line controller), and (web) servers.
- Implementing incident response and resolution workflows to minimize downtime and efficiently handle critical incidents. The fleet operation tool should leverage automation, e.g., incident detection, require minimal human input for recovery, etc. Also the workflow or procedure should allow each team to be responsible for the sfotware they write.
- Establishing a security and compliance framework to ensure the protection of sensitive data, intellectual property, and customer privacy. This includes implementing secure coding practices, conducting regular security audits, and complying with relevant industry standards and regulations.
Beyond 2000 Employees
I don’t have any experience with companies at this size. In fact, I am not even sure if any of robotics companies that I know is at this stage–maybe some of the large autonomous vehicle companies like Waymo, Cruise, Aurora, and Zoox? I will update here after gaining more experience with companies at this stage, one day.
Closing notes
In this post, I have listed the challenges of testing robotics systems in fast-paced startups, shared my techniques for getting started with testing work, and provided insights on key practices for ensuring testability as an organization grows.
Let me know what you think by leaving comments below or messaging me on LinkedIn or Twitter!
- Do my experiences/approaches resonate/align (or not resonate/align) with yours?
- Do you have any test-related war stories or effective testing strategies you’d like to share?
I’d love to hear your thoughts.
Acknowledgements
I thank Rastislav Komara, Dhiraj Goel, Michael J. Declerck, and Doug Blinn for sharing their experiences and insights. I also thank Jihoon Lee, Christian Fritz, and Jimmy Baraglia for their feedback on the initial draft.
Significant Revisions
- 2023/06/29: Added the “Ensuring reliability as an organization grows” section
- 2023/05/28: Rewrote the whole post
Footnotes
[^1] The identified challenges and my approaches may not generalize to other settings, such as testing in robotics companies that are much smaller (i.e., < 10 employees) or much bigger (i.e., > 1000 employees), or involving a different product, such as an autonomous vehicle-based ride-hailing service or an autonomous-based inspection service.
For example, I don’t have much experience with testing robotics systems that make heavy use of machine learning or real-time programming.
[^2] See also The Rise of Test Impact Analysis by Martin Fowler.
[^3] E.g., see ROSCon 2017 Vancouver Day 2 Determinism in ROS and ROSCON 2019 MACAU: CONCURRENCY IN ROS 1 AND 2: FROM ASYNCSPINNER TO MULTITHREADEDEXECUTOR.
[^4] For code examples, see Stateful testing (Python) or Detecting the unexpected in (Web) UI (JavaScript).
[^5] Check out IntegrationTest by Martin Fowler for related discussion, e.g., about narrow and broad integration tests.
[^6] Check out On the Diverse And Fantastical Shapes of Testing (at least the last paragarph starting with “If you’re paying my careful prose …”) by Martin Fowler for related discussion.
[^7] I enjoy following research papers in this space, such as those taking a grammar-based approach like Scenic: a language for scenario specification and scene generation.
[^8] See also this twit thread from Gergely Orosz.
[^9] See also my another post Robo-Observability.